robotstxt怎么写,robotstudio写文字
本文导读: 什么是robots协议?网站中的robots.txt写法和作用Robots协议,全称网络爬虫排除标准(RobotsExclusionProtocol),其目的是让网站明确告知搜索引擎哪些页面可以抓取,哪些不可以。
什么是robots协议?网站中的robots.txt写法和作用
Robots协议,全称网络爬虫排除标准(Robots Exclusion Protocol),其目的是让网站明确告知搜索引擎哪些页面可以抓取,哪些不可以。Robots协议文件是一种ASCII编码的文本文件,通常位于网站的根目录下,它帮助网站向搜索引擎的漫游器(爬虫)传递不可访问页面的信息。
Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。
robots协议是用于指导搜索引擎蜘蛛程序抓取网站内容的规则文件,通常以robots.txt格式存储在网站根目录下。以下是关于robots协议的详细解robots协议文件的作用:确保隐私:用于确保网站的隐私信息不被泄露。定义规则:定义了搜索引擎抓取网站内容的规则,即告诉搜索引擎蜘蛛哪些页面不应被访问。
原因:百度无法抓取网站,因为其robots.txt文件屏蔽了百度。方法:修改robots文件并取消对该页面的阻止。机器人的标准写法详见百度百科:网页链接。更新百度站长平台(更名为百度资源平台)上的网站机器人。过一段时间,你的网站会被正常抓取收录。
合理使用robots协议文件可以防止搜索引擎显示网站的快照,通过在网页头部或robots.txt文件中添加特定元标记来实现。同时,也可以允许其他搜索引擎显示快照但仅防止特定搜索引擎显示。
核心作用:控制抓取行为:Robots协议的核心是网站对搜索引擎抓取行为的控制。实现方式:robots.txt文件:通过在网站根目录的robots.txt文件中设定规则,告诉搜索引擎哪些页面可以访问,哪些应被排除。爬虫访问流程:当爬虫访问网站时,首先会查找robots.txt文件,并遵循其中的指示进行抓取。

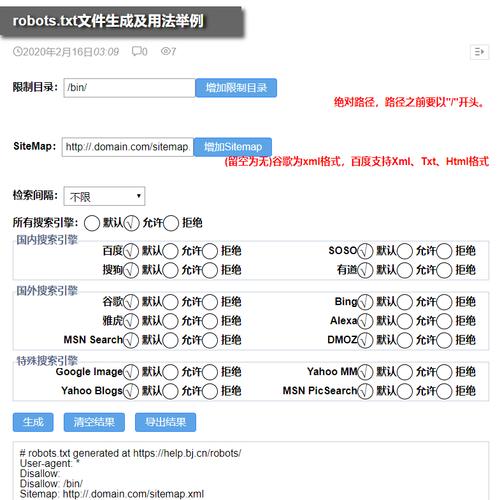
robots.txt文件要怎么写
『1』、写法:Useragent: *Disallow: .jpg$Disallow: .jpeg$Disallow: .gif$Disallow: .png$Disallow: .bmp$写robots.txt时需要注意以下几点: 全部使用英文大写,冒号后有空格。 “/”代表整个网站。 不要因为多一个空格而错误地屏蔽整个网站。 不要禁止正常内容的抓取。 robots.txt的生效时间通常为几天到两个月。
『2』、文件名所有字母必须是小写。为确保搜索引擎能够正确识别并读取robots.txt文件,文件名应全部使用小写字母,避免使用大写或混合大小写。文件位置:文件必须要放在网站根目录下。robots.txt文件应直接放置在网站的根目录中,这样搜索引擎才能通过网站的URL直接访问到该文件。
『3』、必须放置在网站根目录(如https://example.com/robots.txt),文件名需为小写。编码格式 使用UTF-8编码的纯文本文件,避免特殊字符导致解析错误。指令顺序 Disallow与Allow的顺序影响规则优先级,后出现的指令可能覆盖前者。
『4』、Robots.txr文件是一个纯文本文件,可以告诉蜘蛛哪些页面可以爬取(收录),哪些页面不能爬取。
『5』、robots.txt的写法是做seo的人员必须知道的(什么是robots.txt),但该如何写,禁止哪些、允许哪些,这就要我们自己设定了。百度蜘蛛是一机器,它只认识数字、字母和汉字,而其中robots.txt就是最重要也是最开始和百度“对话”的内容。
『6』、robots.txt撰写方法:〖壹〗,允许所有的搜索引擎访问网站的所有部分或者建立一个空白的文本文档,命名为robots.txt。User-agent:*Disallow:或者User-agent:*Allow:/ 〖贰〗,禁止所有搜索引擎访问网站的所有部分。User-agent:*Disallow:/ 〖叁〗,禁止百度索引你的网站。

Robots.txt写法的详细介绍
『1』、robots.txt撰写方法:〖壹〗,允许所有的搜索引擎访问网站的所有部分或者建立一个空白的文本文档,命名为robots.txt。User-agent:*Disallow:或者User-agent:*Allow:/ 〖贰〗,禁止所有搜索引擎访问网站的所有部分。User-agent:*Disallow:/ 〖叁〗,禁止百度索引你的网站。
『2』、其他很多情况呢,需要具体情况具体分析。只要你了解了这些语法规则以及通配符的使用,相信很多情况是可以解决的。meta robots标签 meta是网页html文件的head标签里面的标签内容。它规定了此html文件对与搜索引擎的抓取规则。与robot.txt 不同,它只针对写在此html的文件。写法:。
『3』、robots.txt文件写法举例:User-agent: * 允许所有爬虫 Disallow: /admin/ 禁止访问admin目录 每个指令需新起一行,避免误解。使用注释提供开发者说明,如 # This instructs Bing not to crawl our site.针对不同子域名使用不同robots.txt文件。
『4』、我们的网站起初的robots.txt写法如下:User-agent:Disallow: /wp-admin/ Disallow: /wp-includes/ User-agent: * 的意思是,允许所以引擎抓取。而Disallow: /wp-admin/和Disallow: /wp-includes/,则是禁止百度抓取我们的隐私,包括用户密码、数据库等。
『5』、在该文件中可以使用#进行注解,具体使用方法和 UNIX 中的惯例一样。该文件中的记录通常以一行或多行 User-agent 开始,后面加上若干 Disallow 和 Allow 行 , 详细情况如下:User-agent:该项的值用于描述搜索引擎 robot 的名字。
『6』、robots.txt文件是网站根目录下的纯文本文件,用于指导搜索引擎蜘蛛抓取行为,通过合理设置规则可优化SEO效果并保护敏感信息。
如何写网站robots.txt
必须放置在网站根目录(如https://example.com/robots.txt),文件名需为小写。编码格式 使用UTF-8编码的纯文本文件,避免特殊字符导致解析错误。指令顺序 Disallow与Allow的顺序影响规则优先级,后出现的指令可能覆盖前者。
允许所有的搜索引擎访问网站的所有部分或者建立一个空白的文本文档,命名为robots.txt。User-agent:*Disallow:或者User-agent:*Allow:/ 〖贰〗,禁止所有搜索引擎访问网站的所有部分。User-agent:*Disallow:/ 〖叁〗,禁止百度索引你的网站。
robots.txt写好后,只需要上传到网站的根目录下即可。