怎么优化手机性能,怎么优化手机运行速度
本文导读: 怎么才能让手机的性能更好怎样才能提升手机的性能?如果有更新,建议及时的更新手机系统一般手机的系统更新,要提升手机的性能以及修复相关的BUG,因此,只要手机出现系统更新的提示,建议及时的更新系统。卸载无用或不常用的软件以增加手机的内存空间。
怎么才能让手机的性能更好
怎样才能提升手机的性能?如果有更新,建议及时的更新手机系统一般手机的系统更新,要提升手机的性能以及修复相关的BUG,因此,只要手机出现系统更新的提示,建议及时的更新系统。
卸载无用或不常用的软件以增加手机的内存空间。手机中的照片和视频要定期的清理,不要在手机中长时间堆积,可以传到电脑上,也可以传到云盘上。定期用管家类软件清理系统的垃圾。采取手机root,插入新的框架,优化系统配置。
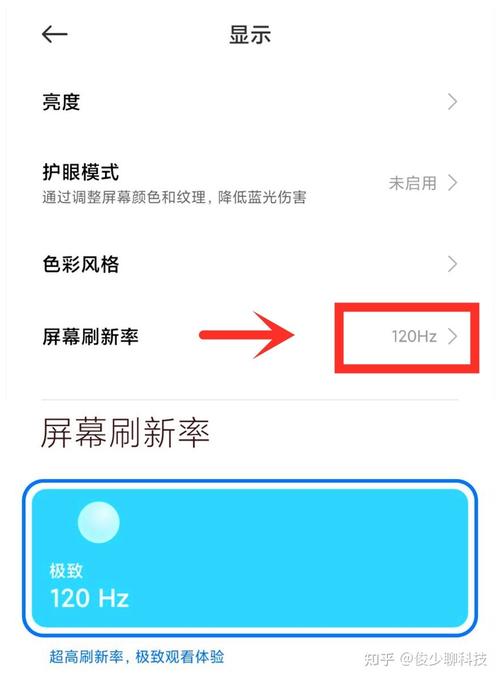
选取设置CPU比较高频率,建议不要太高,否则可能导致手机死机。设置CPU最低频率,建议不要太低,否则可能影响操作体验。设置CPU情景模式:设置I/O计划,设置sio或noop流畅省电两者兼顾。勾选【开机时应用】,完成设置即可通过超频cpu提升性能。
如何让手机更快更顺畅提高手机性能的方法? 定期清理手机内存 随着时间的推移,手机中会积累大量的垃圾文件和缓存,这些文件会占用存储空间,导致手机运行缓慢。使用手机自带的清理工具或第三方清理应用(如“360清理大师”、“CCleaner”等)可以帮助您清除这些无用的文件,释放存储空间。
如何提升手机性能
『1』、如何提升手机性能定期的清理手机里面的垃圾,如果手机的垃圾太多会影响手机的性能,因此,定期的清理手机的垃圾也可以提升手机的性能。时不时的用手机管家清理手机内存。结束后台运行程序,或重启手机。可定期清除手机上网产生的缓存文件。若某些自行下载的软件长期不使用,建议卸载或禁用。
『2』、如果有更新,建议及时的更新手机系统一般手机的系统更新,要提升手机的性能以及修复相关的BUG,因此,只要手机出现系统更新的提示,建议及时的更新系统。定期的清理手机里面的垃圾如果手机的垃圾太多,垃圾越多越影响手机的性能,这就向电脑,因此,定期的清理手机的垃圾也可以提升手机的性能。
『3』、清除不必要的缓存文件 手机中的缓存文件有助于加快网页加载速度和应用性能,但过量的缓存文件会导致存储空间不足。在手机设置中,您可以找到缓存清理选项,定期清除这些文件。 保持系统更新 手机操作系统定期更新以修复漏洞、改进性能和增加新功能。
『4』、其次,清理缓存:定期清理应用程序的缓存,这有助于释放内存和存储空间。可在应用内设置或使用第三方工具进行操作。简化界面:动态壁纸和小部件会消耗资源,尽量减少实时刷新功能,特别是那些占用流量的社交和新闻应用,改用静态壁纸以节省电量。
『5』、使用系统维护工具 现代智能手机都提供了系统维护工具,可以帮助用户清理缓存、垃圾文件、残留文件等,从而提升手机的性能。这些工具可以定期运行,也可以手动运行。需要注意的是,不要在使用手机时运行维护工具,以免影响使用效果。
手机反应很慢怎么办?
设备的后台运行程序过多会导致运行内存不足,导致应用卡顿,建议定时清理后台应用,定期(2-3天)关机重启设备。〖贰〗设备内存不足也会导致系统运行速度慢。进入手机管家选取清理加速,根据扫描建议手动清理您不需要的数据 。
G手机反应太慢的话,个人建议你可以把5G手机的系统版本升级到最新版本,应该是可以解决的,如果说还是太慢的话,个人建议你可以直接刷机刷机完毕之后应该是可以解决反应太慢的问题,因为刷机之后会把里面内存的东西和运行内存的东西全部给你清除完毕,腾出的空间可以让你手机完美运用。
使用需要连接网络的应用程序时,如果Wi-Fi网速较慢或手机信号差导致网络速度较慢,都会导致手机出现卡顿反应慢现象。请尝试更换Wi-Fi热点、更换手机漏友位置保证手机信号良好或更换SIM卡等方法来排查确认。
手机反应慢原因:手机此时运行的应用过多,导致运行内存负荷较大,需要清理手机运行。手机应用转载过多导致手机内存不足,还可能是手机系统出现短暂性故障,将手机关机重启进行尝试。手机使用过久,自然会出现手机卡顿反应慢的情况,甚至有些手机会出现死机的状况。
建议您尽量避免充电时使用手机,适当降低屏幕亮度,关闭不使用或异常耗电应用与功能,如“蓝牙”,NFC等。检查存储卡〖壹〗可能是存储卡存储的文件过多(建议预留10%以上空间),导致读写速度慢,建议您清理存储卡空间,或备份重要数据(QQ、微信等第三方应用需单独备份)后格式化存储卡。