南昌百度优化公司,南昌百度总代理是谁
本文导读: 百度优化和百度推广有区别吗?请大师指点迷津。。。谢谢『1』、百度优化,是不属于百度公司的,很多网络公司都可以做,包括会技术的人员。百度推广,是百度公司,就是你用的这个百度知道提问开发者的公司推出的,完全不同的公司性质。『2』、也就是竞价是花钱的,优化是不花钱给百度的。
百度优化和百度推广有区别吗?请大师指点迷津。。。谢谢
『1』、百度优化,是不属于百度公司的,很多网络公司都可以做,包括会技术的人员。百度推广,是百度公司,就是你用的这个百度知道提问开发者的公司推出的,完全不同的公司性质。
『2』、也就是竞价是花钱的,优化是不花钱给百度的。
『3』、这块要求比较高,推广者必须要有写作能力,不能随便乱写乱改文章就去发表,对于推广者耐力也是一个考验,风险基本可以忽略,效果作用是很有成效的,而且可以带来稳定的读者与链接。邮件论坛推广方法。利用强大的邮件群发,使得顾客与读者对你的邮件内容产生兴趣,从而获得利益。
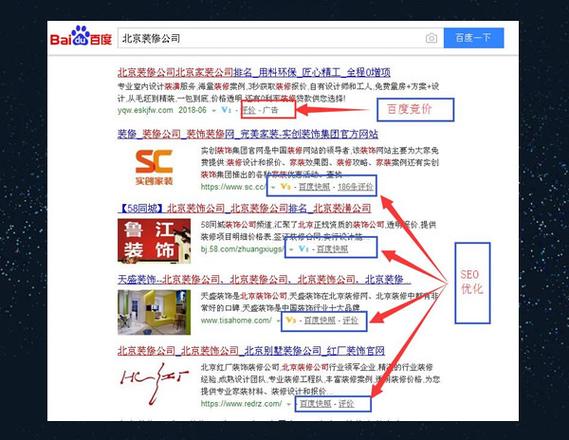
做百度搜狗360快速排名优化,该怎么找外包公司呢?要看外包公司的那些条件...
『1』、首先,考察外包公司的实际效果。查看其服务过的案例,特别是战神快排在百度、360和搜狗的快速排名案例,评估网站排名的稳定性和可靠性。一家专业且有保障的公司,其技术成果将直接影响客户的信任度。其次,技术的成熟度是决定服务质量的关键。不同的外包公司由于经验年限不同,技术成熟度各异。
『2』、要查看seo外包公司的专业程度并不容易,因为seo入门低,基本上会做网站的公司都声称自己会seo,做出来的seo看似符合相关的要求。但是,真正专业的seo公司必然拥有程序高手、营销团队,并且能够把握大局。因此,企业在选取的时候要多比比,多看看,从口碑、信誉上挑拣出专业的seo公司。
『3』、做多个关键词的长尾关键词,如关键词是漂亮,那么长尾关键词可以是中国人长得漂亮。这些长尾关键词要有搜索量,在百度上查看,有搜索量的长尾关键词可以做优化。这些长尾关键词要在文章中出现。这些大量的长尾关键词都要有收录。这些大量的长尾关键词还要有排名。
『4』、网站空间要稳定:选取一个好空间,网站空间的稳定性是基本条件,且有独立IP,不要采用共享虚拟主机那种,如果一个空间有N多个站点,其中一个站点违规,同IP段内的网站可能会到牵连,不利于优化排名。

百度seo公司哪家比较好用
『1』、微数网络:微数网络一直致力于为品牌提供媒体传播一站式服务解决方案。凭借在社交化媒体营销和搜索引擎营销方面的丰富经验和技术,该公司为不同类型的企业提供全面的整站排名优化、口碑营销、互动营销、问答营销、新闻投放、话题炒作和媒介宣传等服务。
『2』、还不错的SEO推广公司有(排名不分先后):百度营销中心、阿里巴巴、知了网络、腾讯营销中心、360搜索等。百度营销中心 作为中国最大的中文搜索引擎,百度营销中心提供了优质的SEO推广服务。它旨在帮助企业提高网站的访问率,提高搜索结果,提升潜在客户的粘性,并达到转化率比竞争对手更高的搜索结果。
『3』、搜狗SEO:国内领先的搜索引擎优化公司,拥有多年的行业经验和专业的团队,致力于提升客户的网站排名,增加流量和转化率,也注重长期效果和用户体验。
『4』、汇通天下=互联网营销。专业从事网站建设,网站推广,各种网站广告,百度推广,360推广,搜狗等推广,SEO网络公司哪家专业。经营14年时间服务过新疆上万家客户,全疆各地均有网点,专业客服团队不需要您配备相关人员,SEO网络公司哪家专业,SEO网络公司哪家专业,您的所有相关工作我们实现全托管服务。
『5』、对网站的内容、结构、关键词等方面进行优化,以提高网站在搜索引擎中的自然排名,从而获得更多的流量和曝光率。一些好的SEO网站排名优化公司比如北京卓立海创网络科技有限公司,提供多种服务,包括关键词优化、网站内容优化、站内外链接等,帮助企业提高网站排名,从而提升品牌知名度和转化率。
『6』、云尚网络做的SEO网站优化效果不错。优化之后的网站使用起来更加的流畅,而且,能够更好的突出亮点,让用户能很快的了解到你是做什么产品的,很好的扩大品牌知名度。如果你预算不是很高,又想要好效果的话,云尚网络就是一个很好的选取。

百度seo优化公司怎么选要注意什么
刚开始双方一定要信任对方,他所做的一切工作你都要信任,他要你的后台账号和FTP你都要给他,不要找借口,因为一个想长期发展的公司,不会为了你一个网站而把你的网站略为所有,这个你们可以放心的,如果产生的疑虑比较大的话,可以打电话聊聊,谅解对方,这样也增加的互相的信任度。
信誉与口碑:选取一个具有良好信誉和口碑的SEO优化公司或服务提供商很重要。可以通过查看客户评价、阅读案例研究以及借鉴其他用户的反馈来了解他们的工作质量和服务水平。 经验与专业知识:优先选取那些具有丰富经验和专业知识的SEO优化公司。
企业本身没有能做seo的人,本身企业规模比较小,专门找一个人来做人员成本比较高。这个情况建议找服务公司来做,一般这类的投入金额不会很多,相当于只是出一个服务费的预算就找了一个职业团队给你做seo,性价比比较高。
信誉与口碑:选取信誉良好且口碑优秀的SEO优化公司或服务商。您可以通过查看客户评价、阅读成功案例和借鉴其他用户的反馈来评估他们的工作质量和服务水平。 经验与专业知识:优先考虑那些经验丰富且具备专业知识的SEO优化公司。他们应深入了解搜索引擎算法和规则,并能提供全面有效的优化策略。
在这里选取哪个词很很关键,这会直接影响到我们的判断。我们要选取的是有指数的词,而不是那种品牌词。例如,“天津seo”这个词就是一个有指数的词,每天会有很多人在百度上搜索。而“张三的seo公司”这种就属于品牌词了,这种词一般是没人搜索的。

分析网站SEO优化公司为什么频繁倒闭的问题
『1』、同行的互相残杀 SEO服务公司单子验收的标准是关键词前十,也就是说一个关键词比较多只能容纳10个客户,第11个客户要加入只能一起厮杀!举例:有11家公司同时做“意思网”这个关键词,那么无论他们11家公司怎么做,都只能上10家公司的词,这是最理想的排名状态。
『2』、整个行业大有这样的现象,认为SEO就是排名,做好排名就做好了SEO。二,我们做网站的目的是为了什么?还记得我们做第一个站点的目的不,我相信大部分人都是出于兴趣。
『3』、所以说实在的百度的优化方法是所有搜索引擎优化的核心。只要你的百度排名做好,其他排名不用看基本上都会上搜索引擎的首页,说了这么多可能有的人看到了有点眼馋。

