独立网店系统,个人网店系统
本文导读: 国内比较好用的网店系统是哪个?筑云网店系统如何?筑云“B2C网上商城系统”采用云计算架构,企业无需购买服务器,也无需担心后期的系统维护问题,这大幅度降低了建站成本。企业只需一个独立域名即可搭建商城网站。个性化与可视化编辑:系统前端页面支持可视化编辑,独创拖拽编辑模式,所见即所得。
国内比较好用的网店系统是哪个?筑云网店系统如何?
筑云“B2C网上商城系统”采用云计算架构,企业无需购买服务器,也无需担心后期的系统维护问题,这大幅度降低了建站成本。企业只需一个独立域名即可搭建商城网站。个性化与可视化编辑:系统前端页面支持可视化编辑,独创拖拽编辑模式,所见即所得。
第一位、SHOPEX简介:国内使用人数比较多的免费独立B2C网店管理软件特色:主要面向个人用户 产品的附属配件多功能全面,免费网店系统的老大哥第二位、360SHOP简介:国内最专业的网店服务提供商特色:360Shop采用经典的LAMP技术 LINUX+APACHE+MYSQL+PHP的MVC架构模式,具有卓越的扩展性。
敦煌网 敦煌网是国内首个为中小企业提供B2B网上交易的网站。它采取佣金制,免注册费,只在买卖双方交易成功后收取费用。据Paypal交易平台数据显示,敦煌网是在线外贸交易额中亚太排名第全球排名第六的电子商务网站,其在2011年的交易达到100亿规模。
商城购物系统:ECSHOP ECShop属于B2C独立网店系统,适合企业及个人快速构建个性化网上商店,系统是基于PHP语言及MYSQL数据库构架开发的跨平台开源程序。不仅设计了人性化的网店管理系统帮助商家快速上手,还根据中国人的购物习惯改进了购物流程,实现更好的用户购物体验。

如何正确开独立网店?
『1』、拓展市场如果是企业,更应该开设自己的独立网店系统。开独立网店系统可以在拓展网络市场的同时,同时也为企业产品在网络中做无成本的口碑宣传。另外,企业可以根据需求,通过独立网店系统的开发团队定制如代理商平台、加盟商平台等功能,更好的拓宽产品的销路。
『2』、要做好网店,需要从市场调研、选品、平台选取、运营策略、成本控制和数据分析等方面入手。 盈利情况分析 行业影响:不同行业的利润空间差异较大。例如,服装行业利润一般在20%-50%,电子产品利润在10%-30%,食品行业利润在30%-60%。
『3』、第一步:精心挑选域名 域名是网店的门面,选取时应尽可能地简洁易记。优先考虑将品牌和行业关键词融合,如 yourbrand.com。避免使用数字或连字符,确保全球用户可以轻松输入。同时,com 是世界通用顶级域名,是个不错的选取。
『4』、开个人网店的具体步骤和所需手续如下: 选取合适的电商平台 首先,你需要选取一个适合个人网店的电商平台,如淘宝、京东、拼多多、亚马逊等。这些平台提供了完善的开店工具和流量支持,适合新手。此外,你也可以选取搭建独立站(如Shopify、Wix等),但需要更高的技术门槛和运营成本。
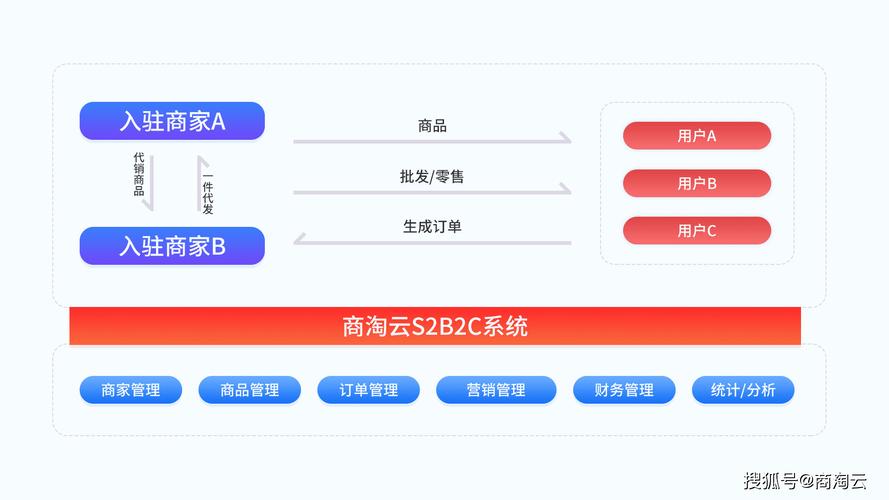
多用户商城系统应用方向_独立商城有哪些好处?
『1』、独立商城的好处:有助建设自有品牌:独立商城可以为企业提供一个专属的在线销售平台,有助于塑造和宣传企业的自有品牌,提升品牌知名度和影响力。独立商城可以绑定独立域名:企业可以拥有自己的独立域名,这有助于提升企业的网络形象和品牌价值,同时也有利于搜索引擎的优化和用户的记忆。
『2』、提升企业形象:独立商城有助于整合企业形象识别系统,提升企业形象,带来销售业绩增长和高效网络推广渠道。体现企业实力:独立商城拥有独特的网站外观、支付方式和购物车,易于与其他企业区分,彰显企业实力。独享客源:独立商城的宣传推广带来的用户均为自身所有,可反复利用,形成稳定的客户群体。
『3』、对于用户体验,可提供个性化服务。根据用户的浏览历史和购买行为,为其推荐个性化商品,优化购物流程,提高用户满意度和忠诚度。从发展角度,拓展市场渠道更便利。可通过多种方式进行推广,吸引不同来源的客户。而且,独立商城系统能随着企业发展不断升级优化,适应业务增长需求,为企业的持续发展提供有力支撑。
『4』、增加利润商城系统自然会带来利润,成本销售也会比以前大大地降低。销售成本的降低意味着利润的增多,即使你不是一个生产销售型企业,也可以通过网上的广告效应带来业务,从而增加利润。拥有自己的独立商城系统,流量数据更“安全”。
『5』、独立商城更容易提升企业形象。可以将网店与你企业的CIS(企业形象识别系统)进行完美整合,这一切不仅体现了你的企业形象,更可以为你带来可观的销售业绩并为你的企业打造更具回报的网络推广渠道。
『6』、搭建更具特色的商城系统 公司进行服务平台类电子商务业务流程的模式可分成B2B、B2C、O2O、等,但现阶段最流行的电子商务方式却是将这几种都充分结合的B2B2C模式。一般的多用户商城系统已经比其他模式好了很多,但是好的多用户商城系统软件优点更加显著,。