robotstxt文件?robotstudio文件变成只读怎么办
本文导读: 什么是robots.txt文件?『1』、robots.txt的基本概念robots.txt文件是一个放置在网站根目录下的纯文本文件,它使用简单的规则来告诉搜索引擎爬虫(也称为蜘蛛或机器人)哪些页面可以访问和抓取,哪些页面应该被忽略或禁止访问。
什么是robots.txt文件?
『1』、robots.txt的基本概念robots.txt文件是一个放置在网站根目录下的纯文本文件,它使用简单的规则来告诉搜索引擎爬虫(也称为蜘蛛或机器人)哪些页面可以访问和抓取,哪些页面应该被忽略或禁止访问。这个文件是网站管理员与搜索引擎之间的一种沟通方式,用于优化搜索引擎的抓取行为,保护网站的隐私和安全。
『2』、Robots.txt文件是一种控制搜索引擎爬虫访问网站的重要方法。它是一个简单的文本文件,通过包含特定的指令来指示搜索引擎哪些部分的内容可以被抓取,哪些部分不应该被抓取。
『3』、了解百度robots.txt文件的关键在于明确其为机器人协议,适用于所有搜索引擎,而不仅仅是百度。此文件位于网站根目录,用于定义抓取规则,规定哪些内容可被抓取,哪些不可。在robots.txt中,关键字指定对象,通常指搜索引擎爬虫,如谷歌的googlebot,百度的Baiduspider等。
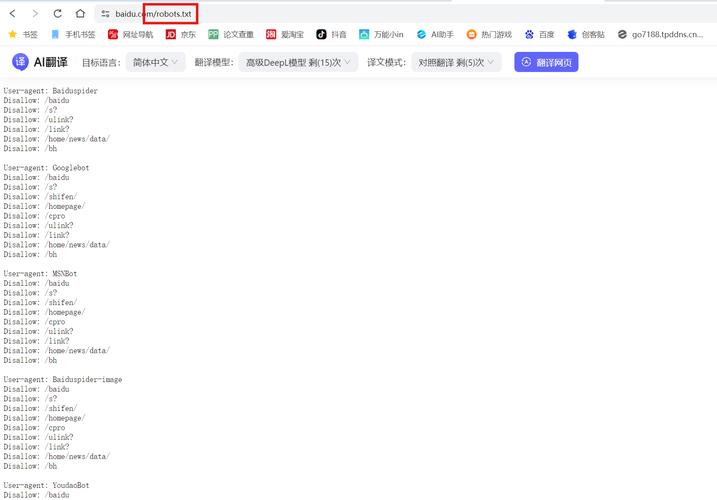
请问:网站根目录的robots.txt文件如何查看呀?
如果网站根目录存在robots.txt文件,它就会被显示出来。 本地查看:你也可以通过FTP工具或其他文件管理工具登录到你的网站服务器,在根目录下找到robots.txt文件,然后用记事本或其他文本编辑器打开它。
要在网站中查找robots.txt文件,首先需要了解它的位置。通常情况下,robots.txt文件位于网站的根目录下。因此,您可以通过在主域名后输入/robots.txt来访问它。例如,如果您的网站域名是www.你的域名.com,那么您可以通过访问www.你的域名.com/robots.txt来查看该文件。
访问网站根目录下的robots.txt文件是了解网站爬虫访问规则的重要步骤。通过直接在浏览器地址栏输入域名并加上/robots.txt,例如想要查看百度网站的robots.txt文件,可以输入 http:// 。此文件通常位于网站的根目录下,提供给搜索引擎和爬虫机器人遵循的指令。

Robots.txt文件作用
『1』、综上所述,Robots.txt文件在控制搜索引擎爬虫访问网站、保护敏感信息、避免重复内容以及遵循搜索引擎规范等方面发挥着重要作用。因此,在创建和使用Robots.txt文件时,应严格遵守相关规范和要求,以确保其能够发挥最大的作用。
『2』、因为robots.txt只是给搜索引擎蜘蛛爬去做限制的,告诉蜘蛛哪些文件夹或路径不要去爬取。
『3』、robots.txt的基础作用与扩展需求传统功能:robots.txt是自1994年存在的标准文件,用于告知搜索引擎爬虫(如Google、Bing)允许访问的网站部分。
『4』、总结:robots.txt在AI时代仍是一种弱约束工具,其效力依赖于爬虫运营方的道德自觉与商业考量。随着AI对数据需求的增长,源网站需通过技术、法律与商业合作的多维策略保障权益,而robots.txt可能逐步演变为更复杂的数据访问控制框架的一部分。

robots.txt在AI时代还有约束吗
总结:robots.txt在AI时代仍是一种弱约束工具,其效力依赖于爬虫运营方的道德自觉与商业考量。随着AI对数据需求的增长,源网站需通过技术、法律与商业合作的多维策略保障权益,而robots.txt可能逐步演变为更复杂的数据访问控制框架的一部分。
研究显示,2023至2024年期间,约5%的在线数据和25%的优质数据加入了robots.txt限制,其中针对OpenAI的限制比例高达29%。这表明通过合理设置robots.txt,能在一定程度上阻止部分AI机器人的抓取行为。
机器人警察功能通过Cloudflare的AI审核实现,可强制执行robots.txt策略并在机器人到达网站前阻止违规访问。其核心机制依托AI审核工具解析robots.txt规则,结合网络级防火墙(WAF)转换规则,将原本自愿遵守的协议升级为强制措施。
百度百科通过修改robots.txt文件屏蔽谷歌、必应等搜索引擎,以防止内容被未经授权抓取用于训练AI。以下是具体分析:屏蔽措施与范围百度百科通过更新robots.txt文件,明确禁止谷歌搜索、必应搜索、微软MSN、UC浏览器的Yisouspider及其他非白名单爬虫抓取内容。

什么是百度robots文件?robots.txt文件放在哪里?
了解百度robots.txt文件的关键在于明确其为机器人协议,适用于所有搜索引擎,而不仅仅是百度。此文件位于网站根目录,用于定义抓取规则,规定哪些内容可被抓取,哪些不可。在robots.txt中,关键字指定对象,通常指搜索引擎爬虫,如谷歌的googlebot,百度的Baiduspider等。
Robots.txt,这个重要的协议,实际上是一个用来指导搜索引擎抓取行为的规则文件,而非直接的命令。它的全称为“网络爬虫排除标准”,网站通过它来指定搜索引擎哪些页面可以访问,哪些要避免抓取。搜索引擎在探索网站时,首先会寻找根目录下的robots.txt文件。
登录网站。因为这个网站的robots.txt文件有限制指令(限制搜索引擎抓取),所以系统无法提供这个页面。我该怎么办?原因:百度无法抓取网站,因为其robots.txt文件屏蔽了百度。方法:修改robots文件并取消对该页面的阻止。机器人的标准写法详见百度百科:网页链接。
robots.txt的基本概念robots.txt文件是一个放置在网站根目录下的纯文本文件,它使用简单的规则来告诉搜索引擎爬虫(也称为蜘蛛或机器人)哪些页面可以访问和抓取,哪些页面应该被忽略或禁止访问。这个文件是网站管理员与搜索引擎之间的一种沟通方式,用于优化搜索引擎的抓取行为,保护网站的隐私和安全。