net域名seo?net域名为什么很少人用
本文导读: 在seo来说,net与com的域名有区别的吗一般来说域名的后缀对网站的排名权重影响不大的,但是有些后缀的域名经常被用来做垃圾站,比如info,tk等,所以这些后缀的网站在搜索引擎的表现很差。但是netcom同是域名始祖,差别不大。
在seo来说,net与com的域名有区别的吗
一般来说域名的后缀对网站的排名权重影响不大的,但是有些后缀的域名经常被用来做垃圾站,比如info,tk等,所以这些后缀的网站在搜索引擎的表现很差。但是net com同是域名始祖,差别不大。
.com和.net域名是世界域名而.cn是国内域名,世界排名.com的使用范畴最大 .net次之、 .cn最小;国内排名: .com最大、.cn其.net最小。单个域名费用: .com 后缀 ¥55/首年; .net 后缀 ¥69/首年; cn 后缀 ¥29/首年;根据网站类别选取域名。
申请网站Com更好,差异:Com 和 Net 是两个比较受欢迎的域名扩展。如果您的首选.com 域名扩展名不可用,那么许多域名生成器工具将建议使用.net 作为替代方案。但是,在大多数情况下,它并不适合您的业务。.com 域名中的COM表示商业域名。
做SEO来说,肯定是选com了,因为com在百度收录和谷歌收录时间是最快的!权限相对来说也会高很多。当然,后期对网站的代码和关建词优化更为重要。

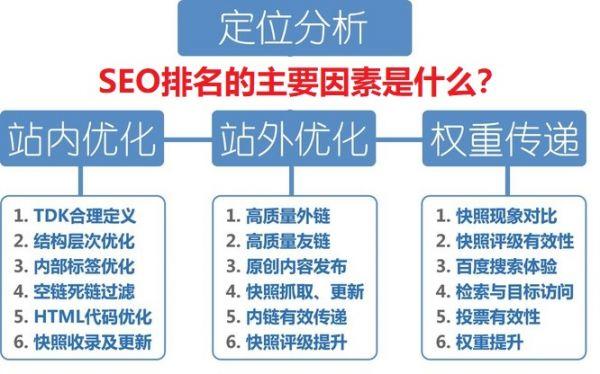
SEO当中能事半功倍的选取——域名的挑选
『1』、seo域名包含关键词 域名中包含关键词、更易于seo优化,比如爱站网seo培训频道的seo子域名等,因为.com的域名权重比较高的,其他的要差些的。
『2』、如何选取有利于SEO的域名 域名不要包含“-”-不方便用户输入。其他的域名均可,比较好不要用中文作为域名。域名就是以后访问自己网站的网址,主要要好记的。短一点的。比较好是双拼。企业名称的汉语拼音作为域名,用企业名称相应的英文名作为域名。
『3』、注册域名越短越好,域名越短易记性越强(例如:hao12com就是易记性的典范)域名注册建议到易名网,因为从安全性和域名转移来讲都相对好一些。
『4』、域名 一个好的域名对SEO的帮助是及其巨大的,选取好的域名有事半功倍的效果,比如全拼、简拼、或者比较短小的3-4位域名都是极好的,不仅利于访客记忆,对于搜索引擎来说也是很友好的,毕竟一个太长的域名会增加搜索引擎的工作量。
『5』、选取有针对性的域名。这里笔者建议,选取域名的时候,如果是老域名,并有权重比较好,只是一个老域名,那么一定要注意这个域名是否曾经被降权,或者是否被K过。如果被K过或者被降权过的域名,即便重新被建立起来,也很难优化上去。另外,一个好的域名也要遵循简单、易记、与主关键词或者行业有相关性。

域名对seo有什么影响
『1』、首先说观点,域名对SEO有一定的影响,但是不太大,不过也是做SEO需要考虑的一点。下面说影响。域名的年龄 老域名要比新域名好一些,当然,被搜索引擎惩罚过的除外。
『2』、域名在搜索引擎存在时间的长短对SEO是有影响的,时间越长的域名,越有利于网站优化。搜索引擎认为,网站存在时间长短是评价网站质量的一个因素。如果网站运营了没多久就放弃了,域名也随之放弃了。有的网站通过不断的运营,给用户带来更好的内容,那么域名的时间也会随之增加。
『3』、域名对网站SEO的影响是比较大的,主要体现在以下几个方面:关键词匹配:域名中包含的关键词与网站主题相关,可以提高网站的搜索引擎排名。例如,如果一个餐饮网站的域名中包含“美食”、“餐厅”等关键词,搜索引擎可能会认为这个网站与餐饮相关,从而提高其排名。

SEO中域名都有哪些
你好,seo中的域名是比较多的,我们常见的域名有:.com、.net、.cn、.org、.edu、.gov等等 SEO行业公认.edu、.gov网站是比较好的外部链接资源,其原因也就在于这些网站通常质量比较高,权重比较高,但是这些权重并不是天生的。
一级域名(TLD):位于域名右侧的比较高级别是顶级域名后缀,例如.com、.org、.net、.edu、.gov、.cn等。一级域名通常代表着网站的顶级分类或国别/地区,如youfind.hk中的youfind。二级域名(SLD):位于一级域名下,通常用于细分化网站或标识特定的品牌、公司或组织。
seo域名品牌化原则 域名品牌化、简短、容易记忆,比如baidu、taobao、alibaba等顾名思义。
.com域名是近来世界上最流行的顶级域名,注册量超过一亿个,一直稳坐域名界龙头老大的位置。也是企业最喜欢的顶级域名,可以这么说10个知名企业8个正在使用或已经保护了自己的.com域名;.cn我国的国家顶级域名,2003年才正式开通注册,在国内使用.cn建站的企业也很多,尤其是国有企业更是普遍。
容易记 域名的选取第二个要重视的法则是易记。容易记住的域名,让人看一眼就能记住,没有过多复杂的字符在里面,举个简单的例子:比如腾讯QQ的qq.com,淘宝的taobao.com等,都是易记的例子。
国外域名和seo有关系吗
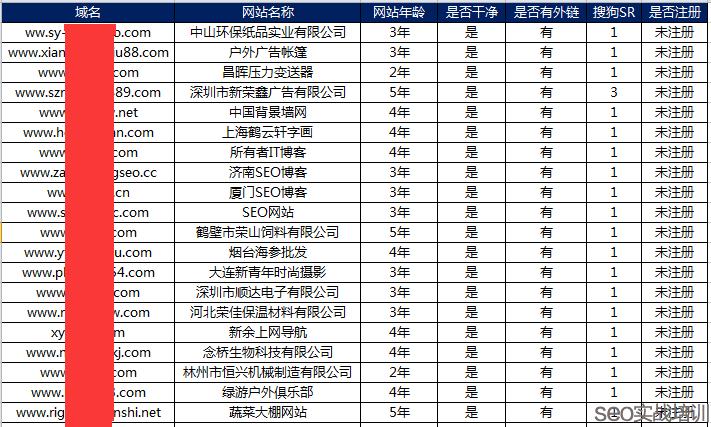
购买国外的域名和空间对网站标题的SEO优化影响并不明显。搜索引擎官方明确表示,它们对海外站点没有歧视。所以无论域名和空间位于何处,只要遵循搜索引擎的优化指南并正确地优化网站,都有可能获得良好的排名。
如果空间速度快的话,影响不大,如果不稳定,导致百度蜘蛛爬取速度慢,造成爬取失败,那是有影响的!英文站选取国外比较好。中文站就要看空间速度了。
虽然域名和SEO有关,但其实SEO是一件长期的需要规划的事情,并不是一个域名就能直接决定的,因此不要过分看重网站域名和SEO的关系。还是要申请适合自己公司的好的域名。一:搜索引擎会给不同域名后缀给予不同的权重 有的域名在出生之前就已经比别的域名高出一头。
首先说观点,域名对SEO有一定的影响,但是不太大,不过也是做SEO需要考虑的一点。下面说影响。域名的年龄 老域名要比新域名好一些,当然,被搜索引擎惩罚过的除外。
这种说法有一定道理,但并不准确。.edu.gov的权重和排名优势并不是天生的,而是由于这种域名的内容忘我质量确实比较高。而.org域名比.com域名更有seo的优势,则没有什么确实根据。
域名对网站seo的影响?
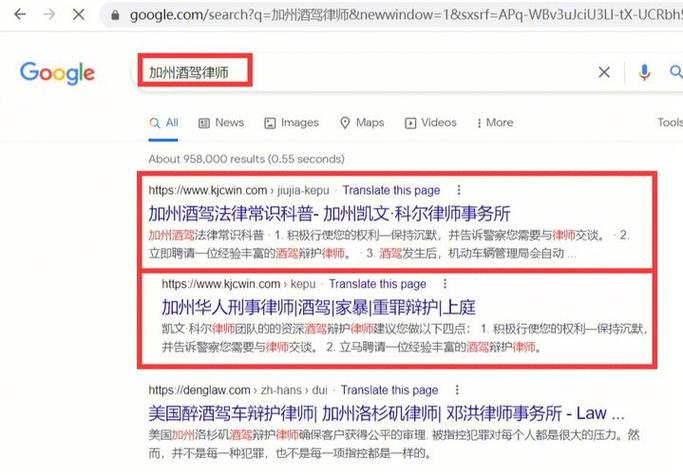
『1』、域名对网站SEO的影响是比较大的,主要体现在以下几个方面:关键词匹配:域名中包含的关键词与网站主题相关,可以提高网站的搜索引擎排名。例如,如果一个餐饮网站的域名中包含“美食”、“餐厅”等关键词,搜索引擎可能会认为这个网站与餐饮相关,从而提高其排名。
『2』、首先说观点,域名对SEO有一定的影响,但是不太大,不过也是做SEO需要考虑的一点。下面说影响。域名的年龄 老域名要比新域名好一些,当然,被搜索引擎惩罚过的除外。
『3』、域名后缀 早期,从域名后缀的角度,它对SEO并没有影响,但随着越来越多的企业用户,采用站群进行百度快速排名,试图操控搜索结果排名,改变搜索排序。由于站群需要大量域名,因此当时很多企业SEO人员,采用类似.pw,.top,.pro这类注册费用相对便宜的域名。
『4』、域名对seo有影响的,但是影响不大,主要有以下几点:短域名便于记忆,而且百度曾指出,简洁的网址对搜索引擎更友好。