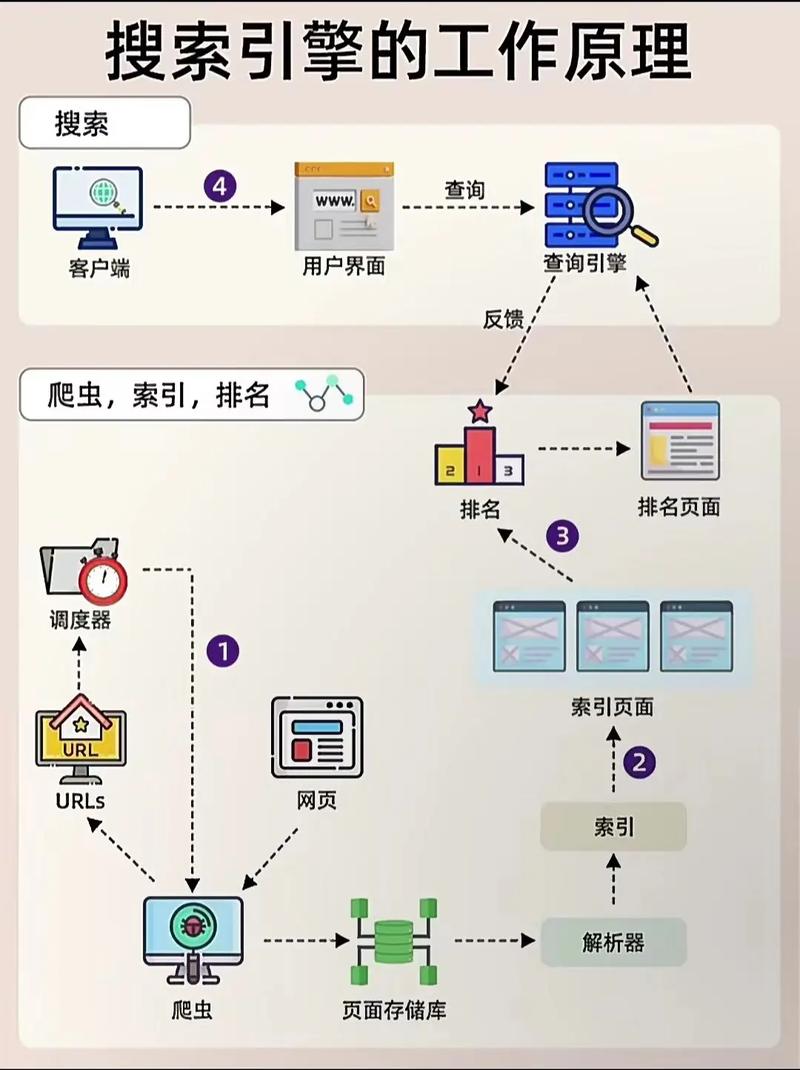
搜索引擎的工作原理?搜索引擎的工作原理分为4个过程
本文导读: 一图搞懂:搜索引擎的工作原理『1』、综上所述,搜索引擎的工作原理是一个复杂而高效的过程,它依赖于爬虫、索引、排名和查询处理等多个环节的紧密协作。通过不断优化这些环节,搜索引擎能够为用户提供更加准确、快速和个性化的搜索体验。『2』、搜索引擎通过四步实现工作原理:爬虫网络爬虫、索引、排名和查询。
一图搞懂:搜索引擎的工作原理
『1』、综上所述,搜索引擎的工作原理是一个复杂而高效的过程,它依赖于爬虫、索引、排名和查询处理等多个环节的紧密协作。通过不断优化这些环节,搜索引擎能够为用户提供更加准确、快速和个性化的搜索体验。
『2』、搜索引擎通过四步实现工作原理:爬虫网络爬虫、索引、排名和查询。第一步,爬虫网络爬虫在互联网上扫描网页,跟踪从一个页面到另一个页面的链接,将URL存储在数据库中。它们发现新内容,包括网页、图像、视频和文件。第二步,索引。一旦网页被抓取,搜索引擎解析页面内容并将其编入数据库索引。
『3』、网站导航系统让搜索引擎“看不懂”;大量动态网页影响搜索引擎检索;没有被其他已经被搜索引擎收录的网站提供的链接;网站中充斥大量欺骗搜索引擎的垃圾信息,如“过渡页”、“桥页”、颜色与背景色相同的文字;网站中缺少原创的内容,完全照搬硬抄别人的内容等。
『4』、一类被称为“白帽SEO”,这类SEO起到了改良和规范网站设计的作用,使之对搜索引擎和用户更加友好,并从中获取更多合理的流量。
『5』、我们就先要确定的公理第一:保证整体运转的效率。第二:保证抓取内容与分类的匹配。这样通过逻辑推导我们可以设想出这样一个工作原理:泛抓取SPIDER抓取的路径通过分析(分析过程类似于路由器寻找节点间的最短路径)。
『6』、搜索引擎营销就是基于搜索引擎平台的网络营销,利用人们对搜索引擎的依赖和使用习惯,在人们检索信息的时候尽可能将营销信息传递给目标客户。搜索引擎营销也是N次方网络整合营销公司对外业务之一。
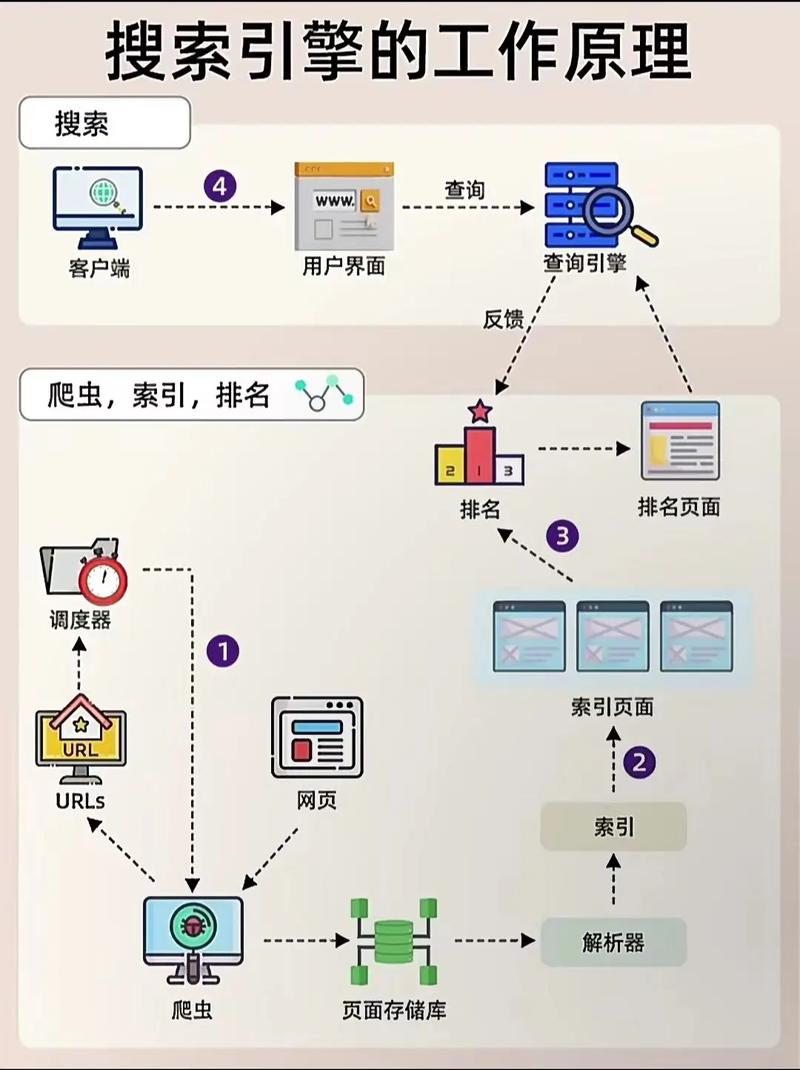
搜索引擎的基本工作原理
搜索引擎的基本工作原理主要包括抓取、索引、排序三个核心环节,其通过预处理网页数据实现高效检索,而非实时遍历全球服务器。以下是具体说明:抓取:有限采集与重要性评估技术瓶颈限制:互联网网页数量庞大(数以百亿千亿计),分布在全球数据中心和机房。受抓取技术限制,搜索引擎无法遍历所有网页,例如部分网页无法通过其他网页的链接找到。
百度搜索引擎的基本工作原理主要包括四个过程:抓取网页、过滤网页、建立索引区以及提供检索服务。抓取网页 百度搜索引擎使用自己的网页抓取程序,即爬虫(Spider)。爬虫顺着网页中的超链接,不断从一个网站爬到另一个网站,通过超链接分析连续访问并抓取更多网页。这些被抓取的网页被称之为网页快照。
搜索引擎技术是一种用于在互联网上搜索和索引信息的技术,其基本工作原理主要包括Web爬虫技术、爬网策略和网页更新策略。Web爬虫技术 定义:Web爬虫技术是通过自动化程序访问互联网上的网页,并收集这些网页的内容和信息,以便后续建立索引和搜索。
搜索引擎的工作原理是一个复杂而精细的过程,它涉及多个环节和组件的协同工作,以实现对互联网信息的有效获取、索引和检索。以下是搜索引擎工作原理的详细解释:数据抓取(Spider系统)搜索引擎的数据抓取系统,通常被称为“Spider”或“爬虫”,是搜索引擎工作的第一步。
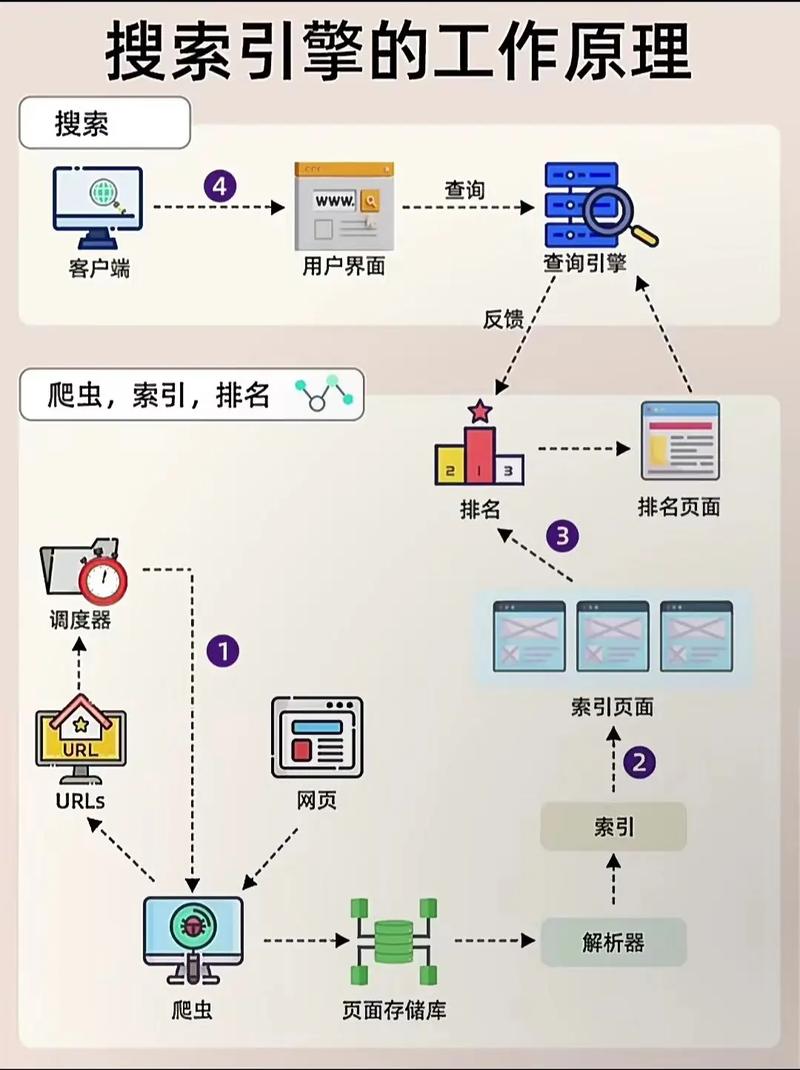
百度搜索引擎基本工作原理的详细解读
百度搜索引擎的基本工作原理主要包括四个过程:抓取网页、过滤网页、建立索引区以及提供检索服务。抓取网页 百度搜索引擎使用自己的网页抓取程序,即爬虫(Spider)。爬虫顺着网页中的超链接,不断从一个网站爬到另一个网站,通过超链接分析连续访问并抓取更多网页。这些被抓取的网页被称之为网页快照。
百度搜索引擎工作原理解读 搜索引擎的主要工作过程包括:抓取、存储、页面分析、索引、检索等几个主要过程,也即常说的抓取、过滤、收录、排序四个过程。下面详细讲解每个过程及其影响因素。搜索引擎抓取 Spider抓取系统是搜索引擎数据来源的重要保证。
百度搜索引擎的工作原理主要包括四个核心环节:抓取建库、检索排序、外部投票以及结果展现。以下是对这四个环节的详细解析:抓取建库 百度搜索引擎通过特定的爬虫程序(Spider)在互联网上抓取网页内容,并将其存储在搜索引擎的索引数据库中。
百度搜索引擎的工作原理主要分为爬行和抓取、预处理网页、提供检索服务三个过程,具体如下:爬行和抓取:百度作为独立的搜索引擎,拥有自己的网页抓取程序,即爬虫,也被称为“蜘蛛”。蜘蛛会顺着网页中的URL链接进行爬行,逐个页面地抓取内容。通过URL链接分析,蜘蛛能够连续访问并抓取更多的网页。
百度搜索引擎的工作原理涉及数据抓取系统的关键作用,它就像一个网络蜘蛛,从重要的种子URL开始,通过超链接不断发现新页面,确保数据来源的稳定和全面。抓取系统主要由链接存储、选取、DNS解析、调度、分析和存储等组件构成,以高效、友好且智能的方式抓取网页,维护URL库和页面库。